Dieser Kurs befasst sich mit der Herausforderung des Maschinellen Lernens (ML) im Zusammenhang mit kleinen Datensätzen, ein wichtiges Thema aufgrund des steigenden Datenbedarfs von ML. Trotz des Erfolgs von ML in verschiedenen Bereichen können in vielen Bereichen aus Kosten-, Datenschutz- oder Sicherheitsgründen keine großen markierten Datensätze bereitgestellt werden. Da Big Data zum Standard wird, ist effizientes Lernen aus kleineren Datensätzen von entscheidender Bedeutung. Dieser Kurs, der ideal für Studenten mit ML-Erfahrung ist, konzentriert sich auf moderne Deep Learning-Techniken für Small Data-Anwendungen, die im Gesundheitswesen, im Militär und in verschiedenen Industriezweigen relevant sind. Zu den Voraussetzungen gehören ML-Kenntnisse und Python-Kenntnisse. Deep Learning-Erfahrung ist nicht erforderlich, aber von Vorteil.

Maschinelles Lernen mit Small Data Teil 1
Sichern Sie sich eines unserer besten Angebote mit Coursera Plus für 199 $ (normalerweise 399 $). Jetzt sparen.

Fragen Sie Coursera
Kompetenzen, die Sie erwerben
- Kategorie: Angewandtes maschinelles LernenAngewandtes maschinelles Lernen
- Kategorie: Lernen übertragenLernen übertragen
- Kategorie: Überwachtes LernenÜberwachtes Lernen
- Kategorie: Tiefes LernenTiefes Lernen
- Kategorie: Maschinelles LernenMaschinelles Lernen
- Kategorie: Modell AusbildungModell Ausbildung
- Kategorie: FeinabstimmungFeinabstimmung
- Kategorie: Kleine DatenKleine Daten
- Kategorie: Daten-SyntheseDaten-Synthese
- Kategorie: Unüberwachtes LernenUnüberwachtes Lernen
- Kategorie: Methoden des maschinellen LernensMethoden des maschinellen Lernens
Wichtige Details

Zu Ihrem LinkedIn-Profil hinzufügen
8 Aufgaben
Erfahren Sie, wie Mitarbeiter führender Unternehmen gefragte Kompetenzen erwerben.

In diesem Kurs gibt es 7 Module
In diesem Modul werden wir die zentrale Rolle von Daten als Grundlage für Algorithmen des Maschinellen Lernens untersuchen. Zunächst wird die Bedeutung großer Datensätze für das Training von Deep Learning-Modellen erörtert, da diese Datensätze entscheidend für die erfolgreiche Anwendung und Effektivität der Modelle sind. Wir werden uns auch mit den Herausforderungen befassen, die mit kleinen Datensätzen verbunden sind, insbesondere in sensiblen Bereichen wie dem Gesundheitswesen und der Verteidigung, wo die Datenerfassung oft schwierig und kostspielig ist oder strengen Datenschutz- und Sicherheitsvorschriften unterliegt. Um diese Herausforderungen zu bewältigen, werden im Kurs verschiedene Strategien zur optimalen Nutzung begrenzter Datenmengen vorgestellt, darunter dateneffiziente Techniken des Maschinellen Lernens und die Verwendung synthetischer Datenerweiterungen. Darüber hinaus werden wir die Kursstruktur vorstellen und eine kuratierte Auswahl von Forschungsarbeiten diskutieren, die mit unseren Kursthemen übereinstimmen und diese bereichern.
Das ist alles enthalten
2 Videos13 Lektüren1 Aufgabe
2 Videos•Insgesamt 16 Minuten
- Daten sind wichtig•8 Minuten
- Einrichten Ihrer lokalen Umgebung•8 Minuten
13 Lektüren•Insgesamt 81 Minuten
- Überblick über den Kurs•1 Minute
- Syllabus - Maschinelles Lernen für Small Data•10 Minuten
- Akademische Integrität•1 Minute
- Daten sind wichtig - vor allem für Deep Learning•2 Minuten
- Daten-Parameter-Leistungsskalierung im KI-Modell•5 Minuten
- Exponentiales Wachstum der Trainingsdaten•10 Minuten
- Exponentielles Wachstum der Komplexität von Modellen•5 Minuten
- Exponentielles Wachstum der Computerressourcen•5 Minuten
- Das Skalierungsparadoxon: Wenn kleinere ML-Modelle besser abschneiden als große•5 Minuten
- Große Datensätze für Deep Learning•10 Minuten
- Was sind Small Data?•2 Minuten
- Installation von PyTorch•5 Minuten
- Große vs. kleine Datensätze beim Maschinellen Lernen•20 Minuten
1 Aufgabe•Insgesamt 10 Minuten
- Modul 1 Quiz•10 Minuten
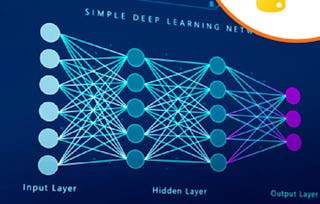
In diesem Modul werden wir uns mit den Kernaspekten des Maschinellen Lernens befassen, wobei der Schwerpunkt auf der Bedeutung von Daten liegt, insbesondere bei Deep Learning-Anwendungen. Wir beginnen damit, dass wir betonen, wie wichtig große Datensätze für ein effektives Training von Deep Learning-Modellen sind, da sie es den Modellen ermöglichen, komplexe Muster zu erfassen und daraus zu lernen, was ihre Gesamtleistung verbessert. Darüber hinaus werden wir die Überschneidung von Datenverfügbarkeit, Rechenleistung und Modellkapazität untersuchen und aufzeigen, wie diese Elemente zusammenwirken, um die Genauigkeit und Effizienz des Modells zu verbessern. Darüber hinaus werden in diesem Modul die Fortschritte bei der Datenverarbeitung jenseits des Mooreschen Gesetzes und ihre Auswirkungen auf das Maschinelle Lernen behandelt. Es wird aufgezeigt, wie moderne Hardware wie CPUs, GPUs und TPUs die Rechenkapazitäten verbessern, die für das Training anspruchsvoller Modelle entscheidend sind. Wir werden uns auch mit den Skalierungsgesetzen im Deep Learning befassen und empirische Ergebnisse diskutieren, die zeigen, wie sich die Modellleistung mit zunehmender Datenmenge und Modellkomplexität vorhersehbar verbessert, wenn auch mit abnehmender Rendite. Um eine tiefere theoretische Grundlage zu schaffen, werden wir die Vapnik-Chervonenkis (VC)-Theorie untersuchen, die Einblicke in die Beziehung zwischen Lernkurven und Modellkomplexität und der Fähigkeit eines Modells zur Verallgemeinerung aus Trainingsdaten bietet. Diese Diskussion wird sich auf praktische Anwendungen und theoretische Grenzen erstrecken und dazu beitragen, die Herausforderungen des Maschinellen Lernens in Bezug auf Datenausreichend, Modellanpassung und das Gleichgewicht zwischen Bias und Abweichung zu formulieren. Am Ende dieses Moduls werden die Studierenden ein gründliches Verständnis des dynamischen Zusammenspiels dieser Faktoren und ihrer Auswirkungen auf die Praxis des Maschinellen Lernens und die Forschung haben.
Das ist alles enthalten
1 Video19 Lektüren2 Aufgaben1 App-Element
1 Video•Insgesamt 9 Minuten
- Leistung des Modells für Maschinelles Lernen•9 Minuten
19 Lektüren•Insgesamt 144 Minuten
- Zutaten Verhältnis•10 Minuten
- Rechenleistung: Wachstum jenseits des Mooreschen Gesetzes•10 Minuten
- Skalierungsgesetze•5 Minuten
- Lernkurven•15 Minuten
- Erforderliche Modellkapazität zur Anpassung der Daten•3 Minuten
- Modellleistung und Datensatzgröße•2 Minuten
- Modellleistung und Modellkapazität•2 Minuten
- Verzerrung-Varianz-Kompromiss•15 Minuten
- FROM eine Perspektive der linearen Algebra•2 Minuten
- Unterbestimmte Probleme und überparametrisierte Modelle•8 Minuten
- Überprüfung der Bias-Varianz mit Double Descent•8 Minuten
- Vergleich von Lernparadigmen•15 Minuten
- Eine lernende Maschine•2 Minuten
- Wie charakterisieren wir die Komplexität von Modellen?•1 Minute
- Vapnik-Chervonenkis (VC) Dimension - Zertrümmerung•10 Minuten
- Begriffe der VC-Dimension•10 Minuten
- Beispiele für Shattering und VC Dimension•10 Minuten
- VC-Dimension in Neuronalen Netzen•15 Minuten
- Ressourcen•1 Minute
2 Aufgaben•Insgesamt 60 Minuten
- Berechnung der VC-Dimension von SVM-Modellen•30 Minuten
- Modul 2 Quiz•30 Minuten
1 App-Element•Insgesamt 10 Minuten
- Beispiele für lernende Maschinen•10 Minuten
In diesem Modul werden wir uns mit Transfer Learning und seiner Rolle beim dateneffizienten Maschinellen Lernen beschäftigen, bei dem Modelle das Wissen aus früheren Aufgaben nutzen, um die Leistung bei neuen, verwandten Aufgaben zu verbessern. Wir werden auch verschiedene Arten von Transfer Learning behandeln, darunter transduktive, induktive und unüberwachte Methoden, die jeweils unterschiedliche Herausforderungen und Anwendungen adressieren. Wir werden einige praktische Schritte zur Implementierung von Transfer Learning besprechen, wie z.B. die Auswahl und das Fine-Tuning von Pre-Training-Modellen, um die Abhängigkeit von großen Datensätzen zu verringern. Wir werden auch datengesteuerte und physikbasierte Simulationen zur Datenerweiterung untersuchen und deren Einsatz zur Verbesserung des Trainings unter eingeschränkten Bedingungen hervorheben. Abschließend werden wir die wichtigsten Arbeiten über Transfer Learning-Techniken zur Bewältigung von Datenknappheit und zur Verbesserung der Modellleistung besprechen.
Das ist alles enthalten
1 Video15 Lektüren1 Aufgabe
1 Video•Insgesamt 6 Minuten
- Lernen übertragen•6 Minuten
15 Lektüren•Insgesamt 72 Minuten
- Dateneffizientes Maschinelles Lernen•10 Minuten
- Nutzung von Pre-Training-Modellen für effizientes Maschinelles Lernen•2 Minuten
- Vanilla Transfer Learning•2 Minuten
- Arten von Transfer Learning•2 Minuten
- Transduktive Transfer Learning Algorithmen•10 Minuten
- Induktive Transfer Learning Algorithmen•10 Minuten
- Transduktive Beispiele I•5 Minuten
- Transduktive Beispiele II•5 Minuten
- Transduktive Beispiele III•5 Minuten
- Induktive Beispiele•5 Minuten
- Multi-Task-Lernen & Meta-Learning•5 Minuten
- Synthetische Datenerweiterung•2 Minuten
- Datengestützte Simulation•3 Minuten
- Physik-basierte Simulation•2 Minuten
- Physik-basierte Simulation Beispiele•4 Minuten
1 Aufgabe•Insgesamt 15 Minuten
- Modul 3 Quiz•15 Minuten
In diesem Modul lernen Sie das Konzept der Domänenanpassung kennen, ein Schlüsselaspekt des transduktiven Transfer Learning. Mithilfe der Domänenanpassung können Sie Modelle trainieren, die in einer Zieldomäne gut funktionieren, auch wenn sich die Verteilung der Daten von der Quelldomäne unterscheidet. Sie lernen die Herausforderungen der Domänenverschiebung und der Knappheit an gelabelten Daten kennen und erfahren, wie sich diese auf die Leistung des Modells auswirken können. Wir werden verschiedene Arten der Domänenanpassung behandeln, darunter unüberwachte, halbüberwachte und überwachte Ansätze. Sie werden auch in Techniken wie Deep Domain Confusion (DDC) eintauchen, die den Verlust der Domänenkonfusion in neuronale Netzwerke integriert, um domäneninvariante Merkmale zu erstellen. Darüber hinaus lernen Sie fortgeschrittene Methoden wie Domain-Adversarial Neural Networks (DANNs), Correlation Alignment (CORAL) und Deep Adaptation Networks (DANs) kennen, die auf DDC aufbauen, um die Domänenanpassung zu verbessern, indem sie die Verteilung von Merkmalen abgleichen und komplexe Abhängigkeiten über Netzwerkschichten hinweg erfassen.
Das ist alles enthalten
1 Video10 Lektüren1 Aufgabe
1 Video•Insgesamt 6 Minuten
- Anpassung der Bereiche•6 Minuten
10 Lektüren•Insgesamt 143 Minuten
- Bereichsanpassung: Hintergrund•1 Minute
- Unbeaufsichtigt, halb-beaufsichtigt und beaufsichtigt•10 Minuten
- Tiefe Domänenverwirrung•8 Minuten
- Verwandte Arbeiten auf Basis von DDC•2 Minuten
- Deep Domain Konfusion Architektur•10 Minuten
- Implementierung und Architektur•10 Minuten
- Mathematische Formulierung•5 Minuten
- Ein Beispieldatensatz: Büro-31•2 Minuten
- Ein Beispiel für ein DDC-Experiment•5 Minuten
- Transfer Learning Praxisaktivität•90 Minuten
1 Aufgabe•Insgesamt 10 Minuten
- Modul 4 Quiz•10 Minuten
In diesem Modul werden wir uns mit der schwachen Überwachung befassen, einer Technik zum Training von Modellen des Maschinellen Lernens mit begrenzten, verrauschten oder ungenauen Beschriftungen. Sie lernen verschiedene Arten von schwacher Überwachung kennen und erfahren, warum sie in Bereichen mit kleinen Datenmengen entscheidend sind. Wir werden Techniken wie halbüberwachtes Lernen, selbstüberwachtes Lernen und aktives Lernen sowie fortgeschrittene Methoden wie Temporal Ensembling und den Mean Teacher-Ansatz behandeln. Darüber hinaus lernen Sie Bayesian Deep Learning und aktive Lernstrategien zur Verbesserung der Trainingseffizienz kennen. Schließlich werden Sie reale Anwendungen in Bereichen wie medizinische Bildgebung, NLP, Betrugserkennung, autonomes Fahren und Biologie kennenlernen.
Das ist alles enthalten
1 Video8 Lektüren1 Aufgabe
1 Video•Insgesamt 7 Minuten
- Was ist schwache Aufsicht?•7 Minuten
8 Lektüren•Insgesamt 54 Minuten
- Arten von schwacher Supervision•6 Minuten
- Semi-überwachtes Lernen•10 Minuten
- Selbstüberwachtes Lernen•15 Minuten
- Aktives Lernen•6 Minuten
- Anwendungen der schwachen Aufsicht•2 Minuten
- Fallstudie: Medizinische Bildgebung•5 Minuten
- Fallstudie: Autonomes Fahren•5 Minuten
- Fallstudie: Verarbeitung natürlicher Sprache•5 Minuten
1 Aufgabe•Insgesamt 30 Minuten
- Modul 5 Quiz•30 Minuten
In diesem Modul erfahren Sie, wie Zero-Shot Learning (ZSL) Modelle in die Lage versetzt, neue Kategorien zu erkennen, ohne dass sie während des Trainings Beispiele für diese Kategorien gesehen haben. Dies wird erreicht, indem semantische Zwischenbeschreibungen, wie z. B. Attribute, genutzt werden, die von gesehenen und ungesehenen Klassen gemeinsam genutzt werden. Sie werden auch erfahren, wie wichtig die Regularisierung ist, um Überanpassung zu verhindern und die Generalisierung zu verbessern, und wie generative Modelle wie GANs und VAEs ZSL verbessern, indem sie ungesehene Klassendaten synthetisieren. Darüber hinaus werden wir uns mit Generalized Zero-Shot Learning (GZSL) beschäftigen, bei dem Modelle sowohl auf gesehene als auch auf ungesehene Klassen getestet werden, was die Aufgabe anspruchsvoller und realistischer macht. Am Ende dieses Moduls werden Sie ein solides Verständnis dafür haben, wie ZSL und seine Erweiterungen auf verschiedene Aufgaben des Maschinellen Lernens angewendet werden können.
Das ist alles enthalten
1 Video9 Lektüren1 Aufgabe
1 Video•Insgesamt 5 Minuten
- Verallgemeinertes Zero-Shot Learning•5 Minuten
9 Lektüren•Insgesamt 71 Minuten
- Einführung in Zero-Shot Learning•3 Minuten
- ZSL: Notation und Problemstellung•3 Minuten
- Lernen eines linearen Prädiktors für gesehene Klassen•10 Minuten
- Problemerweiterung für ZSL: Von gesehenen zu ungesehenen Klassen•15 Minuten
- Eine peinlich einfache Herangehensweise an die ZSL•10 Minuten
- ZSL mit generativen Modellen•10 Minuten
- Verallgemeinertes Zero-Shot Learning (GZSL)•10 Minuten
- Zero-Shot Learning: Semantische Autoencoder•5 Minuten
- Verallgemeinerte ZSL mit generativen Modellen•5 Minuten
1 Aufgabe•Insgesamt 30 Minuten
- Modul 6 Quiz•30 Minuten
Dieses Modul befasst sich mit Few-Shot Learning (FSL), einem wichtigen Paradigma des Maschinellen Lernens, das Modelle in die Lage versetzt, neue Beispiele mit nur einer kleinen Anzahl von markierten Instanzen zu klassifizieren. Im Gegensatz zu traditionellen Deep Learning-Modellen, die riesige Mengen beschrifteter Daten benötigen, ahmt FSL die menschliche Fähigkeit nach, aus begrenzten Beispielen zu verallgemeinern, was es für Aufgaben wie Bildklassifizierung, Objekterkennung und Verarbeitung natürlicher Sprache (NLP) äußerst nützlich macht. In der Vorlesung werden Matching-Netzwerke vorgestellt, ein metrikbasierter Lernansatz zur Lösung von One-Shot-Lernproblemen durch das Erlernen einer Ähnlichkeitsfunktion, die neue Beispiele auf zuvor gesehene markierte Instanzen abbildet. Die Studenten erhalten ein tiefes Verständnis dafür, wie Nearest-Neighbor-Ansätze, differenzierbare Einbettungsfunktionen und Aufmerksamkeitsmechanismen bei der Optimierung von Few-Shot Learning Modellen helfen. Durch Diskussionen, theoretische Formulierungen und reale Anwendungen vermittelt diese Vorlesung den Studierenden praktische Erkenntnisse darüber, wie KI in datenarmen Umgebungen effektiv funktionieren kann.
Das ist alles enthalten
1 Video7 Lektüren1 Aufgabe
1 Video•Insgesamt 6 Minuten
- Einführung in Few-Shot Learning•6 Minuten
7 Lektüren•Insgesamt 46 Minuten
- Was ist Few-Shot Learning?•10 Minuten
- Einführung in One-Shot Learning•2 Minuten
- VERGLEICH von Netzwerken: Ein Ansatz für One-Shot-Learning•10 Minuten
- Training Verglichene Netzwerke•3 Minuten
- Verbesserung der visuellen Klassifizierung von Few-Shots•10 Minuten
- Verbesserung der Klassifizierung von Bildern mit wenigen Aufnahmen anhand von unbeschrifteten Beispielen•10 Minuten
- Herzlichen Glückwunsch•1 Minute
1 Aufgabe•Insgesamt 30 Minuten
- Modul 7 Quiz•30 Minuten
Dozent


Mehr von Maschinelles Lernen entdecken
 Status: VorschauVorschauN
Status: VorschauVorschauNNortheastern University
Kurs
 Status: VorschauVorschauO
Status: VorschauVorschauOO.P. Jindal Global University
Kurs
 Status: Kostenloser TestzeitraumKostenloser TestzeitraumP
Status: Kostenloser TestzeitraumKostenloser TestzeitraumPPearson
Kurs
 Status: Kostenloser TestzeitraumKostenloser Testzeitraum
Status: Kostenloser TestzeitraumKostenloser TestzeitraumKurs
Warum entscheiden sich Menschen für Coursera für ihre Karriere?

Felipe M.

Jennifer J.

Larry W.

Chaitanya A.


Häufig gestellte Fragen
Um Zugang zu den Kursmaterialien und Aufgaben zu erhalten und um ein Zertifikat zu erwerben, müssen Sie die Zertifikatserfahrung erwerben, wenn Sie sich für einen Kurs anmelden. Sie können stattdessen eine kostenlose Testversion ausprobieren oder finanzielle Unterstützung beantragen. Der Kurs kann stattdessen die Option "Vollständiger Kurs, kein Zertifikat" anbieten. Mit dieser Option können Sie alle Kursmaterialien einsehen, die erforderlichen Bewertungen abgeben und eine Abschlussnote erhalten. Dies bedeutet auch, dass Sie kein Zertifikat erwerben können.
Wenn Sie ein Zertifikat erwerben, erhalten Sie Zugang zu allen Kursmaterialien, einschließlich der benoteten Aufgaben. Nach Abschluss des Kurses wird Ihr elektronisches Zertifikat zu Ihrer Erfolgsseite hinzugefügt - von dort aus können Sie Ihr Zertifikat ausdrucken oder zu Ihrem LinkedIn-Profil hinzufügen.
Ja. Für ausgewählte Lernprogramme können Sie finanzielle Unterstützung oder ein Stipendium beantragen, wenn Sie die Einschreibegebühr nicht aufbringen können. Wenn für das von Ihnen gewählte Lernprogramm eine finanzielle Unterstützung oder ein Stipendium verfügbar ist, finden Sie auf der Beschreibungsseite einen Link zur Beantragung.
Weitere Fragen
Finanzielle Unterstützung verfügbar,