This course equips learners with the theoretical knowledge and computational skills needed to implement modern Bayesian statistical methods in real-world settings. By completing the course, learners will be able to build and fit Bayesian models, apply computational algorithms for posterior inference, and interpret uncertainty in complex data analysis problems. Topics include maximum a posteriori (MAP) estimation, rejection sampling, and Markov chain Monte Carlo (MCMC) methods such as the Gibbs sampler and Metropolis-Hastings algorithms. Learners will also gain hands-on experience using Stan, one of the leading platforms for Bayesian modeling and probabilistic programming.

Computational Bayesian Statistics for Data Science
Sichern Sie sich eines unserer besten Angebote mit Coursera Plus für 199 $ (normalerweise 399 $). Jetzt sparen.

Verschaffen Sie sich einen Einblick in ein Thema und lernen Sie die Grundlagen.
Stufe Mittel
Empfohlene Erfahrung
2 Wochen zu vervollständigen
unter 10 Stunden pro Woche
Flexibler Zeitplan
In Ihrem eigenen Lerntempo lernen
Was Sie lernen werden
Articulate the need for computational approaches, such as Markov chain Monte Carlo (MCMC) algorithms, to Bayesian inference.
Implement algorithms to find posterior distributions, including Gibbs sampling, Metropolis-Hastings, and various advanced MCMC algorithms.
Implement Bayesian computation in the Stan computing environment.
Apply computational Bayesian statistical methods to real-world data science problems.
Kompetenzen, die Sie erwerben
- Kategorie: Statistical Inference
- Kategorie: Statistical Analysis
- Kategorie: Mathematics and Mathematical Modeling
- Kategorie: Machine Learning Methods
- Kategorie: Computational Logic
- Kategorie: Probability & Statistics
- Kategorie: Computational Thinking
- Kategorie: Predictive Modeling
- Kategorie: Statistical Methods
- Kategorie: Bayesian Statistics
- Kategorie: Data Science
Wichtige Details

Zertifikat zur Vorlage
Zu Ihrem LinkedIn-Profil hinzufügen
Kürzlich aktualisiert!
Mai 2026
Bewertungen
5 Aufgaben
Unterrichtet in Englisch
Erfahren Sie, wie Mitarbeiter führender Unternehmen gefragte Kompetenzen erwerben.

In diesem Kurs gibt es 5 Module
Dozent


Mehr von Probability and Statistics entdecken
University of Colorado Boulder
 Status: Kostenloser Testzeitraum
Status: Kostenloser Testzeitraum Status: Kostenloser Testzeitraum
Status: Kostenloser TestzeitraumIllinois Tech
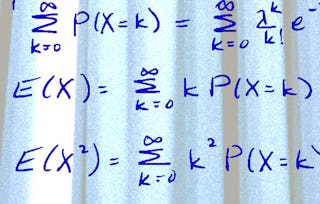 Status: Kostenloser Testzeitraum
Status: Kostenloser TestzeitraumUniversity of Colorado Boulder
Warum entscheiden sich Menschen für Coursera für ihre Karriere?

Felipe M.
Lernender seit 2018
„Es ist eine großartige Erfahrung, in meinem eigenen Tempo zu lernen. Ich kann lernen, wenn ich Zeit und Nerven dazu habe.“

Jennifer J.
Lernender seit 2020
„Bei einem spannenden neuen Projekt konnte ich die neuen Kenntnisse und Kompetenzen aus den Kursen direkt bei der Arbeit anwenden.“

Larry W.
Lernender seit 2021
„Wenn mir Kurse zu Themen fehlen, die meine Universität nicht anbietet, ist Coursera mit die beste Alternative.“

Chaitanya A.
„Man lernt nicht nur, um bei der Arbeit besser zu werden. Es geht noch um viel mehr. Bei Coursera kann ich ohne Grenzen lernen.“


Häufig gestellte Fragen
Weitere Fragen
Finanzielle Unterstützung verfügbar,